 Prometheus-Vision
Prometheus-Vision
We introduce Prometheus-Vision, an evaluator Vision-Language Model (VLM) that is open-source, offers reproducible evaluation, and is inexpensive to use. We construct Perception-Collection, the first multimodal feedback dataset for training an evaluator VLM, which includes 15K fine-grained scoring criteria defined for each instance. Prometheus-Vision trained on Perception-Collection shows high correlation with human evaluators and GPT-4V, paving the way for accessible and transparent evaluation of VLMs.
Recent VLMs exhibit impressive visual instruction-following capabilities. To assess and compare the quality of VLM-generated outputs, we utilize VLMs as evaluator of VLMs, naming the approach as ‘VLM-as-a-Judge’.

Traditional metrics for VLM evaluation measure the similarity between a response and the ground-truth answer. However, such automatic metrics fail to capture the rich context within the output. Also, these metrics do not explain what is missing or present in the response.
An evaluator VLM can adhere to specific criteria of interest to focus on nuanced details in the visual context and instruction. Moreover, it can provide detailed language feedback that helps the user understand the reasoning behind the scoring.
The Perception-Collection dataset is targeted for fine-grained multimodal feedback generation. Each instance consists of 5 input components: an instruction, a real-world image, a response to evaluate, a customized score rubric, and a reference answer. Based on this, an evaluator VLM is trained to generate a language feedback and a score decision on a scale of 1 to 5.

We collect 5K real-world images sampled from the COCO dataset and the MMMU benchmark. Then, we augment the data in a 4-stage process: (1) hand-craft 50 seed score rubrics, (2) brainstorm and refine 15K fine-grained score rubrics, (3) augment 30K instructions and reference answers related to the score rubric, and (4) augment 150K responses and language feedback for training. From stage 2 to 4, we prompt GPT-4V to generate the data. We ensure that each generated score rubric aligns with the image and that there is no length bias in responses across the score range.
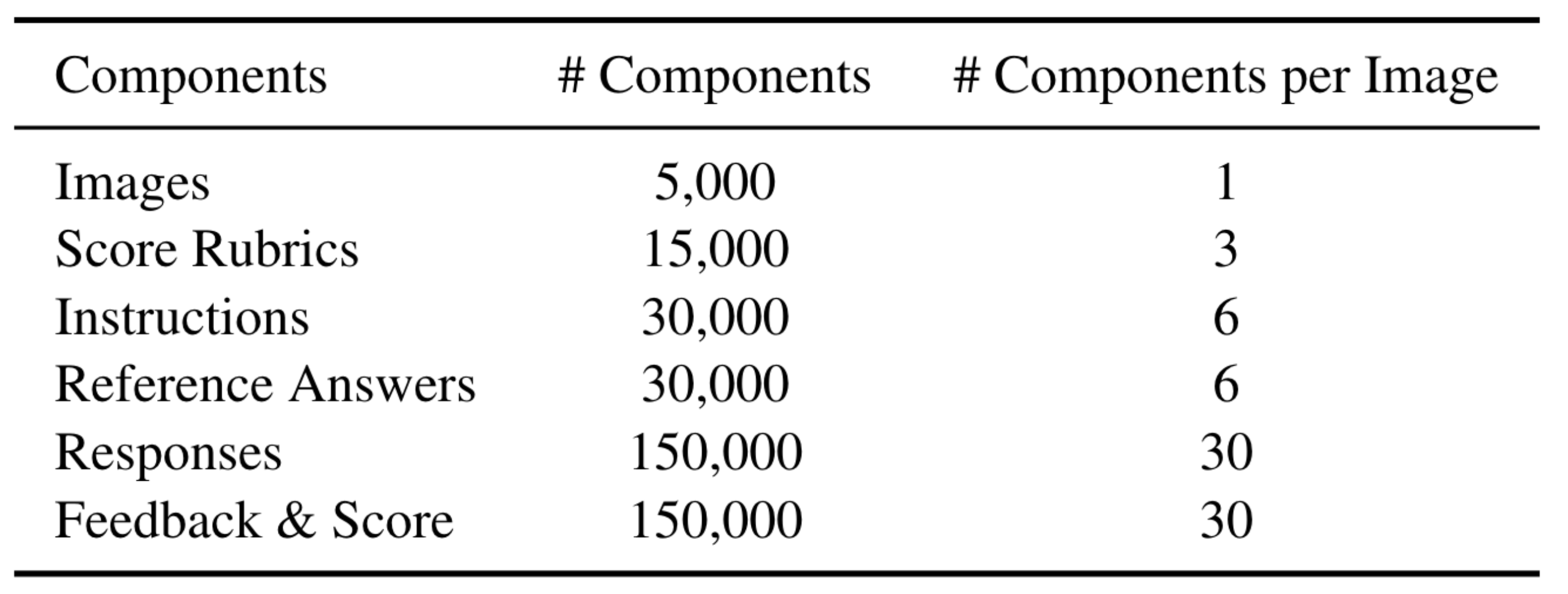
We also release a held-out test set of the Perception-Collection called Perception-Bench, which contains 500 instances and a single score rubric for each instance.
Using the Perception-Collection, we use LLaVA-1.5 (7B & 13B) as our backbone model and train Prometheus-Vision (7B & 13B). Through experiments, we demonstrate that Prometheus-Vision can be an effective open-source alternative to using human or GPT-4V for VLM evaluation.
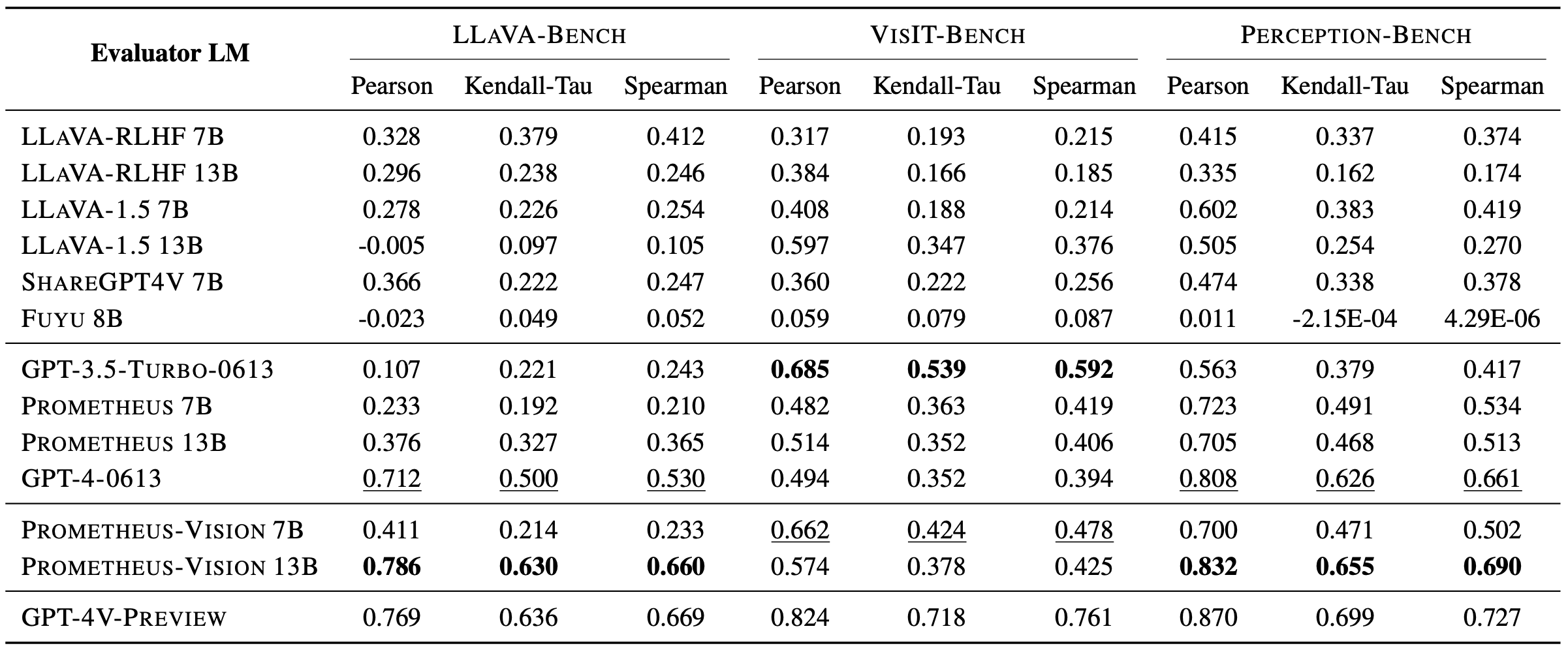
Prometheus-Vision shows high correlation with human evaluators on instances with real-world images, LLaVA-Bench and Perception-Bench. Also, Prometheus-Vision 13B’s feedback is as good as or better than GPT-4V’s feedback 57.78% of the time.


Prometheus-Vision shows the highest correlation with GPT-4V among open-source VLMs and outperforms GPT-3.5-Turbo and GPT-4 (‘LM-as-a-Judge’) in LLaVA-Bench and Perception-Bench.
If you find our work useful in your work, please consider citing our paper:
@misc{lee2024prometheusvision,
title={Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation},
author={Seongyun Lee and Seungone Kim and Sue Hyun Park and Geewook Kim and Minjoon Seo},
year={2024},
eprint={2401.06591},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
![]()
![]()
![]()
![]()




